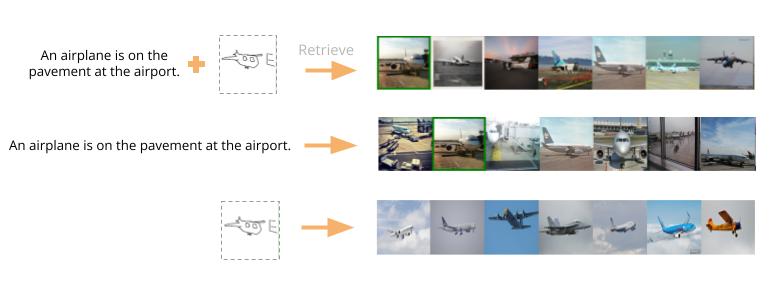
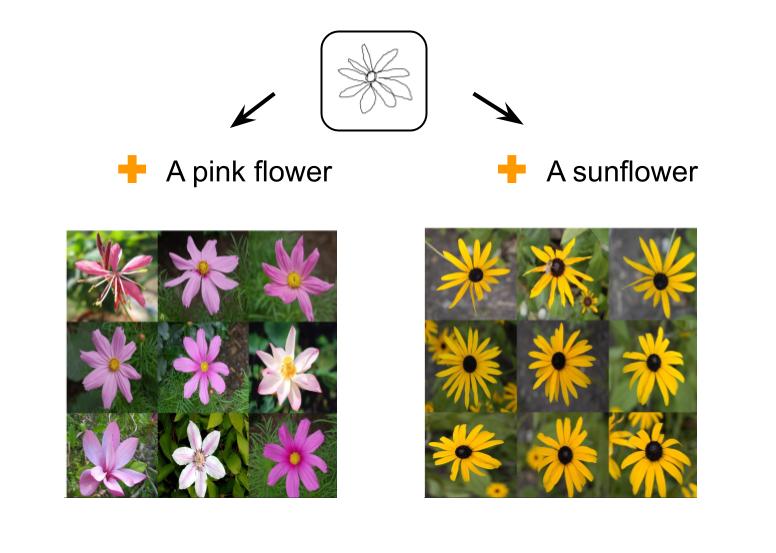
@article{
tsbir2022,
author = {Patsorn Sangkloy and Wittawat Jitkrittum and Diyi Yang and James Hays},
title = {A Sketch is Worth a Thousand Words: Image Retrieval with Text and Sketch},
journal = {European Conference on Computer Vision, ECCV},
year = {2022},
}
